

架构简介:打破”Mac 游戏荒漠”的刻板印象
游戏社区长期流传着一个心照不宣的调侃:“Mac 不能打游戏。“这种刻板印象的底层逻辑,源于 Apple Silicon 极其封闭的 Metal 图形 API 与主流游戏引擎重度依赖的 DirectX / Vulkan 之间那道难以跨越的生态壁垒。然而,我每天面对着手里这台 MacBook Pro(M2 Max)上那块顶级的 Liquid Retina XDR 屏幕时,事情就变得很纠结了。这块屏幕拥有高达 254 PPI 的像素密度,支持 120 Hz ProMotion 自适应刷新率,并且依靠背后庞大的 Mini-LED 阵列实现了 1600 尼特的峰值亮度与极致的 HDR 动态范围。习惯了这种拥有绝对色彩保真度、以及离电状态下 M 系列芯片带来的零噪音、冰冷体感的优雅体验后,再去审视那些风扇狂转、屏幕色彩和对比度往往妥协于成本的传统 Windows 游戏本,不可避免地会产生一种生理上的抗拒。

为了在 Mac 上玩游戏,很多极客尝试过曲线救国的方案:比如使用 CrossOver,或者基于苹果官方的 Game Porting Toolkit(GPTK 2.0)进行转译。但从计算机系统结构的角度来看,这种强行跨平台的代价是极其高昂的。游戏运行时,系统不仅要处理 x86 指令集到 ARM64 架构的实时二进制翻译(Rosetta 2),还要让 CPU 极其疲惫地处理 DirectX 到 Metal 的 API 绘图指令映射。这种”双重翻译”带来了不可避免的 CPU 调度拥塞和极高的渲染延迟。实际体验往往一言难尽:不仅帧生成时间(Frametime)像心电图一样疯狂跳动,更致命的是,高负载会瞬间击穿 Mac 的被动散热阈值,让原本安静的机器风扇起飞,彻底剥夺了 Mac 独有的优雅感。
既然受制于芯片架构,无法在 Mac 上原生痛快地运行 3A 大作,不妨彻底转换底层逻辑:物理剥离渲染与显示的强绑定,将手头的 MacBook Pro 降维打击为地表最强的”智能显示终端”。其实算一笔账就会发现,与其花费大几千乃至上万元去增购一台受制于 8 GB 显存瓶颈、且散热极其暴躁的主流 RTX 5060 游戏本,不如将这笔预算投入到目前最强的游戏主机——PlayStation 5 Pro 上。通过高端视频采集卡将 PS5 Pro 的无损画面注入 Mac,并在 macOS 端利用苹果的底层 API 进行超分与重构。这不仅能以极高的性价比享受到硬核主机独占大作,还能让沉没成本极高的 Mac 屏幕发挥最大价值。
这套异构计算管线的核心组件与工作流如下:
- 原生算力层(信号源):PlayStation 5 Pro 作为远端重载节点,利用其内置的定制机器学习硅片驱动 PSSR(PlayStation Spectral Super Resolution)2.0 技术,将内部渲染画面进行高质量的时域特征重构,输出毫无频闪与伪影的 1440p @ 120 Hz 纯净视频流。
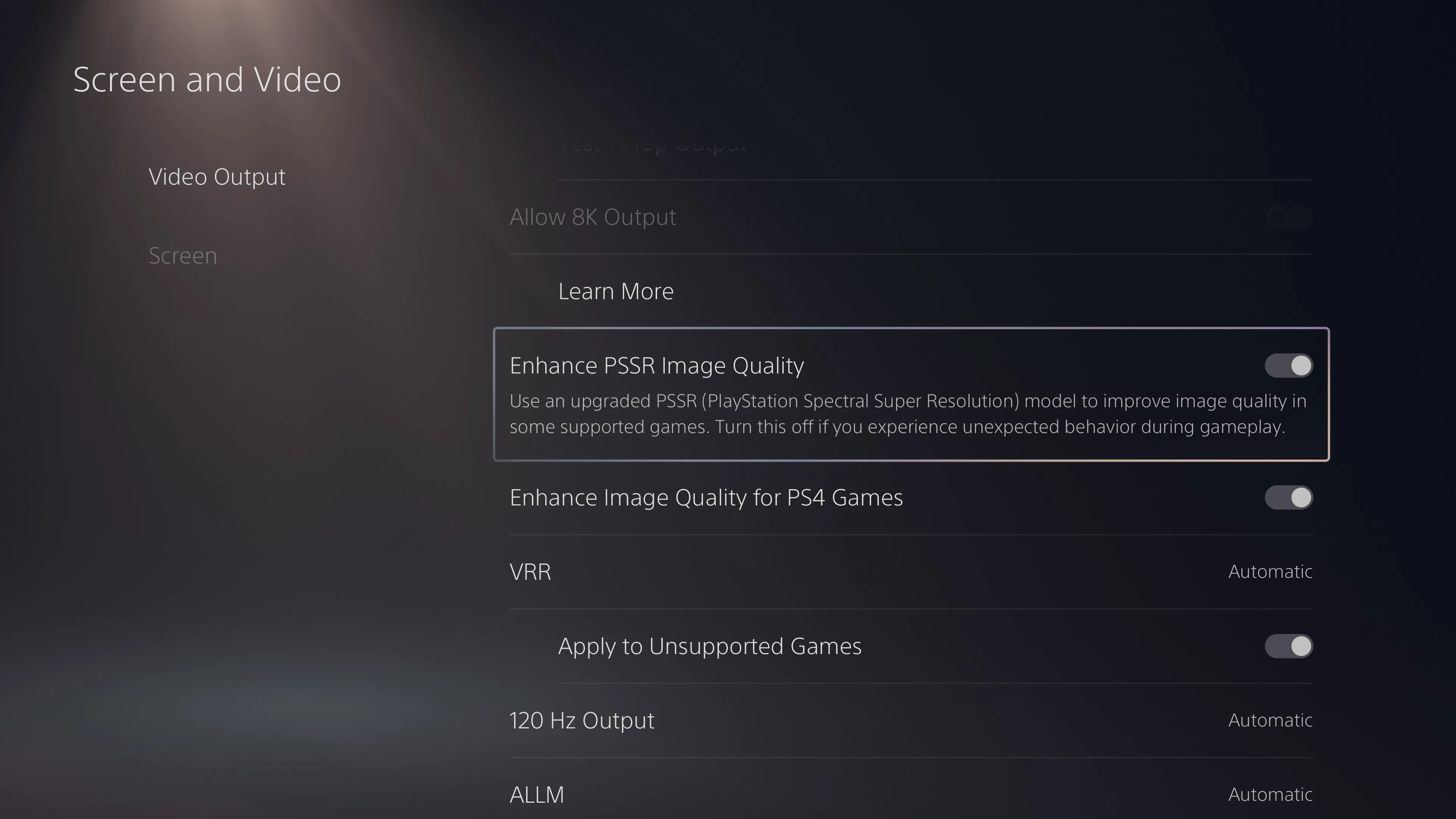
- 物理传输层(数据总线):圆刚 GC553G2(Live Gamer Ultra 2.1)顶级采集卡作为桥梁,通过 USB 3.2 Gen 2(10 Gbps)超宽带物理链路,以 4:2:0 的 NV12 格式无损吞吐 1440p 120 Hz 的 UVC 裸数据流进入 Mac。
- 视窗接管层(终端调度):MacBook Pro 16 英寸(M2 Max 芯片)。通过 ConsoleLink App 接收数据,在 macOS 内核态触发 Game Mode(游戏模式) 剥夺后台进程算力并成倍提升蓝牙采样率,同时开启 Direct-to-Display(直通显示) 技术,绕过系统原生的窗口合成器,将输入延迟压榨至物理极限。
- 终端空域超分(画质升维):ConsoleLink 唤醒苹果的 MetalFX Spatial(空间超分) 接口。依靠 M2 Max 庞大的 GPU ALU 阵列进行高阶方向性插值(全程 0% ANE 神经网络引擎调用,规避上下文切换延迟),将 1440p 视频流顺着几何边缘锐化并拉伸至 4K,最终点对点完美铺满 Liquid Retina XDR 视网膜屏幕。
这套被称为”双重超分接力(Dual-Stage Upscaling Relay)“的异构管线,彻底打破了传统主机与 PC 的物理边界。它由 PlayStation 5 Pro 提供底层渲染,通过 HDMI 2.1 采集卡进行物理层面的数据中转,最终交由 M2 Max 芯片在 macOS 端进行解码、空域超分与极低延迟送显。
硬件拓扑与算力对标:这套异构管线的”钞能力”密码
既然手头的 MacBook Pro 是为了日常写码与开发早已购入的”沉没成本”,那么在构建这套跨端游戏管线时,实际的新增开销便仅局限于物理信号的生成与传输层。为了确保 120 Hz 高频数据流在进入 Mac 屏幕前的绝对纯净,这套链路在硬件选型上没有任何妥协的余地。
渲染源点:PlayStation 5 Pro(约 ¥5,000)
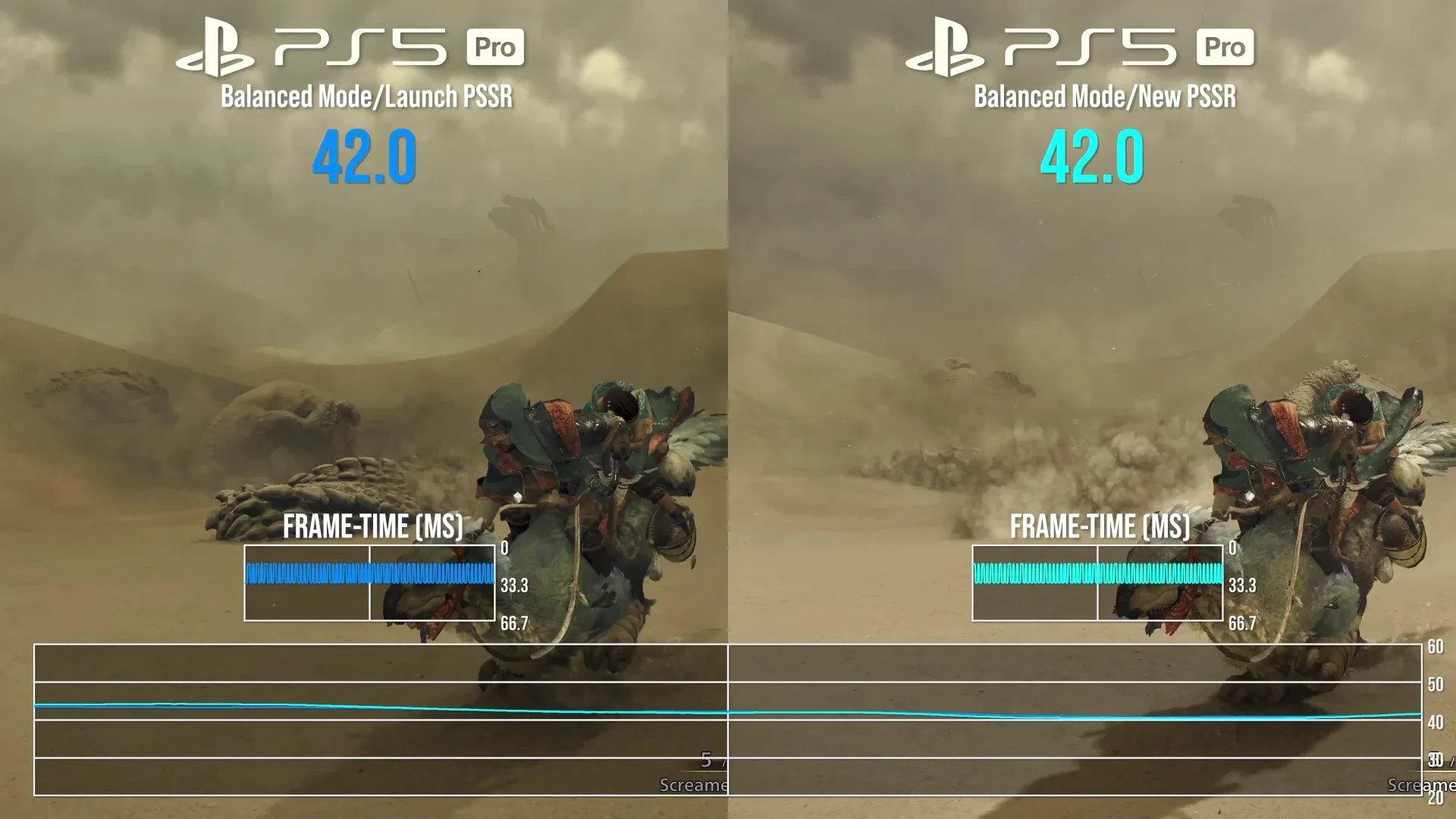
 有朋友可能会问,为什么不省点钱选只要三千出头的标准版 PS5?原因很现实:基础版主机的硅片内缺乏专用的机器学习硬件单元,根本无法在底层硬件级调用 PSSR(PlayStation Spectral Super Resolution)超分算法。更致命的是,基础版的 GPU 算力想要在开启光线追踪的高压环境下维持 1440p 的内部渲染分辨率纯属天方夜谭——为了保住 120 Hz,其画面往往会暴力降级至 1080p 甚至更低的糊墙画质。这就导致后期的 Mac 端 MetalFX 放大面临”垃圾进,垃圾出”的窘境,产生不可逆的像素断层。
有朋友可能会问,为什么不省点钱选只要三千出头的标准版 PS5?原因很现实:基础版主机的硅片内缺乏专用的机器学习硬件单元,根本无法在底层硬件级调用 PSSR(PlayStation Spectral Super Resolution)超分算法。更致命的是,基础版的 GPU 算力想要在开启光线追踪的高压环境下维持 1440p 的内部渲染分辨率纯属天方夜谭——为了保住 120 Hz,其画面往往会暴力降级至 1080p 甚至更低的糊墙画质。这就导致后期的 Mac 端 MetalFX 放大面临”垃圾进,垃圾出”的窘境,产生不可逆的像素断层。
物理传输中枢:圆刚 GC553G2(Live Gamer Ultra 2.1)(约 ¥1,400)
 市面上确实充斥着大量搭载 MS2130 或 MS2131 方案的百元级廉价 USB 采集卡。但这些”电子垃圾”大多停留在 HDMI 2.0 的上古规格,且 USB 总线带宽被死死卡在 5 Gbps,为了串流只能强制走 H.264 或 MJPEG 这种劣化画质的有损压缩协议。而 GC553G2 跑的是满血的 10 Gbps USB 3.2 Gen 2 通道,能够以毫无妥协的 4:2:0(NV12)色彩空间,将 1440p 120 Hz 的原始原生像素流,原封不动地硬塞进 Mac 的统一内存池中。
市面上确实充斥着大量搭载 MS2130 或 MS2131 方案的百元级廉价 USB 采集卡。但这些”电子垃圾”大多停留在 HDMI 2.0 的上古规格,且 USB 总线带宽被死死卡在 5 Gbps,为了串流只能强制走 H.264 或 MJPEG 这种劣化画质的有损压缩协议。而 GC553G2 跑的是满血的 10 Gbps USB 3.2 Gen 2 通道,能够以毫无妥协的 4:2:0(NV12)色彩空间,将 1440p 120 Hz 的原始原生像素流,原封不动地硬塞进 Mac 的统一内存池中。
| RGB (通常指 RGB24) | YUY2 | NV12 | MJPEG (Motion JPEG) | |
|---|---|---|---|---|
| 压缩类型 | 无压缩 (Uncompressed) | 色度子采样 (Chroma Subsampling) | 色度子采样 (Chroma Subsampling) | 帧内有损压缩 (Lossy Compression) |
| 色彩空间与采样 | RGB (相当于 4:4:4 全采样) | YUV 4:2:2 | YUV 4:2:0 | 基于 YUV 的 JPEG 压缩 |
| 每像素平均位深 | 24 bits (红、绿、蓝各 8 bits) | 16 bits | 12 bits | 可变 (取决于压缩率,通常极低) |
| 数据排列方式 | 交错排列: 每个像素独立存储 R G B R G B ... | 交错排列: 每两个像素共享色彩 Y1 U Y2 V ... | 半平面排列 (Semi-Planar): 先存完整的明度 Y 平面,再存交错的色彩 U V U V ... 平面 | 独立图像序列: 每一帧都是一张独立的压缩图片 [JPEG 1] [JPEG 2] ... |
| 画质表现 | 极佳 (完全无损,色彩最准确) | 良好 (保留全部亮度,色彩稍有压缩) | 一般至良好 (色彩信息进一步减少) | 可变 (存在压缩伪影,取决于压缩率) |
整体算下来,管线的总增量预算在 ¥7,000(约合 $1,000)左右。这笔投资换来的,是一套彻底剥离热源与风扇噪音、且能在视网膜屏幕上呈现满血画质的顶级游戏生态。
ConsoleLink:压榨 macOS 渲染极限的视窗手术刀
即使物理层的总线通道已经打通,如果软件层的调度逻辑拉胯,整个系统依然会被灾难性的输入延迟(Input Lag)毁于一旦。常规的采集软件(如 OBS 或 QuickTime)其底层架构是为”录制与推流”服务的,它们会让视频流经过 macOS 庞杂的 WindowServer 视窗合成器、全局色彩管理机制以及多重帧缓冲队列。这一套流程跑下来,凭空就会增加 30~50 ms 的致命延迟,手柄推杆简直像在泥沼里游泳。
这时候,被选作终端调度引擎的 ConsoleLink 就展现出了其作为”底层手术刀”的恐怖实力,它拥有几项不可替代的技术特权:
- Direct-to-Display(直通显示):这招极其暴力。它直接绕过了繁冗的 WindowServer 视窗管理器。GPU 在渲染完当前帧后,不需要排队等待系统合成,而是将显存指针强行跨层级交接给屏幕控制器,直接点亮 Liquid Retina XDR 上的像素点,硬生生在物理层面抢出了 1~2 帧的排队时间。
- Game Mode(游戏模式)强制接管:在全屏状态下,它向 macOS 内核下发最高优先级的游戏描述符。这不仅能让 M2 Max 锁定在极高的时钟频率拒绝降频休眠,更夸张的是,它会将蓝牙外设(手柄、耳机)的轮询采样率直接翻倍,极大程度榨干了无线信号的物理响应潜能。
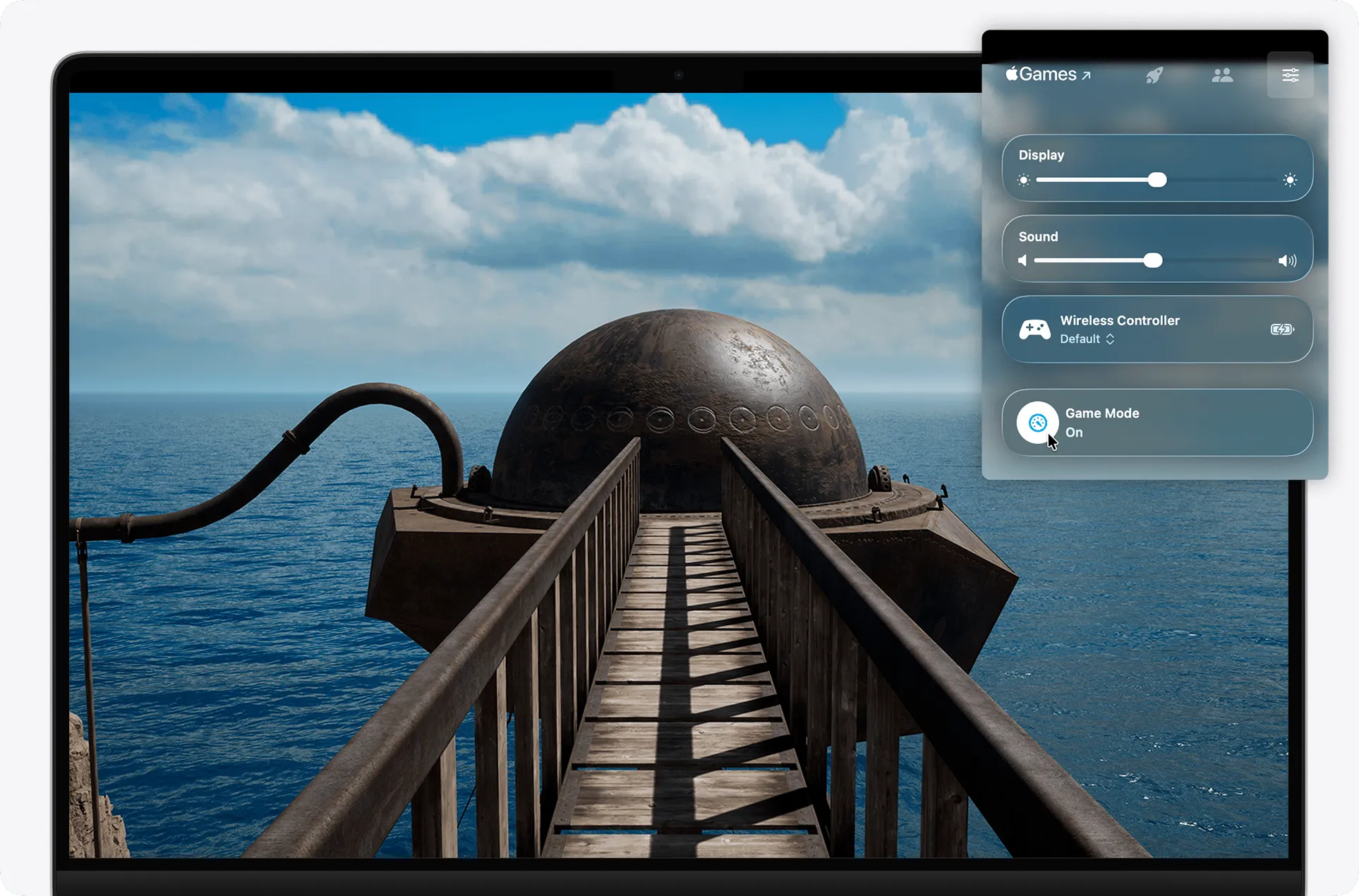
- 极简 Metal API 调用:即便在 1440p 120 Hz 每秒数亿次像素吞吐的高压负载下,依靠精简到极致的 Metal 绘图指令,ConsoleLink 依然能将 CPU 的渲染编码耗时恐怖地压制在 0.01 ms 的量级。
成本解构:在 2026 年的 PC 市场实现降维打击
站在内存和固态硬盘价格全线飞涨的 2026 年,仔细盘算这笔硬件账,就会发现这套管线的性价比有多夸张。
如果握着 $1,000(约 ¥7,000)的同等增量预算转身投入 PC 阵营,目前最多只能勉强攒出一台搭载 RTX 5060(8 GB GDDR6)的台式机,或是买一台散热缩水的入门级游戏本。面对现代 3A 大作动辄要求 4K 120 Hz 的终极目标,区区 8 GB 显存的 RTX 5060 会瞬间触发显存溢出(OOM),再撞上 128-bit 显存带宽的物理限制,帧数绝对会跌成 PPT。
反观作为核心算力源的 PS5 Pro,其硬件堆料其实相当残暴:
| 硬件组件 | 规格参数 |
|---|---|
| 存储(SSD) | 2 TB,PCIe 4.0 |
| CPU | 8 核 AMD Zen 2,3.85 GHz |
| GPU 流处理器 | 3840 个 Shading Units |
| 纹理映射单元 | 240 个 TMU |
| 光栅化输出单元 | 64 个 ROP |
| 统一内存 | 16 GB GDDR6,256-bit,等效 18 Gbps |
| GPU Boost 频率 | 2.35 GHz |
| GPU 最高功耗 | 232 W |
| 制程工艺 | 台积电 4 nm |
| 晶体管数量 | 210 亿 |
| 芯片面积 | 279 mm² |
- 存储系统:出厂直接焊死 2 TB PCIe 4.0 高速 SSD。按今年的市场行情,光这块盘的拿货价就直逼 ¥2,000。
- 中央处理器(CPU):定制的 8 核 AMD Zen 2 架构,频率 3.85 GHz。虽然微架构放在今天看略显老旧(甚至有极客调侃它的绝对单核性能只配和 Intel N200 这种轻薄本入门 CPU 坐一桌),但在主机专属 API 的极低开销优化下,喂饱同平台的 GPU 依然毫无瓶颈。
- 图形处理器(GPU)算力正名:很多不了解主机硬件拓扑的人,误以为它的 GPU 顶多相当于一张 NVIDIA RTX 3060?大错特错。这颗代号 Viola、基于台积电 4 nm 工艺打造的硅片,面积高达 279 mm²,狂暴地塞进了 210 亿个晶体管。它坐拥 3840 个流处理器单元(Shading Units)、240 个纹理映射单元(TMU)以及 64 个光栅化输出单元(ROP),并配备了完整的 16 GB GDDR6 统一内存池(256-bit 位宽,等效 18 Gbps)。在最高 2.35 GHz 的 Boost 频率下,这颗最高功耗标定在 232 W 的定制野兽,其光栅化物理算力其实远远甩开了 RTX 3060,传统性能上足以硬刚 RTX 4070。
综上所述,利用 M2 Max MacBook Pro 顶级的 Liquid Retina XDR 屏幕”白嫖”高端显示器,再配合 PS5 Pro 强大的异构算力与 16 GB 大显存池,便能在 ¥7,000 的预算维度内,打出一套画质、流畅度与极客优雅感全面碾压同价位 PC 系统的终极组合拳。
原理深潜:PSSR 与 MetalFX 的降维配合
我们必须明确一个核心技术事实:我们监控到的采集卡 USB 120 Hz 输出,仅仅是传输通道的频率。真正的底层魔法,在于 PS5 Pro 原生输出的物理帧率与 macOS 端进行的二次拉伸。
这套”双重超分”管线,是时域算法与空域算法的完美交响。
第一阶段:PSSR(PlayStation Spectral Super Resolution)的时域重构
在远端,PS5 Pro 并不直接渲染沉重的 4K 像素。它以 1080p~1440p 为内部基准,调用专属的机器学习硅片(Machine Learning Block)执行 PSSR 2.0 算法。PSSR 是一种时域超分(Temporal Upscaling),它贪婪地提取游戏引擎底层的 G-Buffers(几何深度、运动向量、材质 ID),参考前几帧的历史画面,利用 AI 推理出当前帧丢失的亚像素细节。由于 PS5 Pro 拥有 16 GB 的海量统一内存与 256-bit 宽广总线,PSSR 能够无缝驻留高清纹理,最终通过 HDMI 吐出极度纯净、无锯齿的 1440p 物理信号。
第二阶段:MetalFX Spatial 的空域接力
为什么不使用大名鼎鼎的 NVIDIA DLSS?因为 UVC 协议封装的仅仅是纯粹的 2D 像素裸流(RGB / YUV)。一旦离开 PS5 的主板,所有关乎 3D 几何与运动向量的元数据就已经全部销毁。面对没有运动向量的纯视频流,DLSS 会瞬间变成瞎子,算法网络彻底瘫痪。

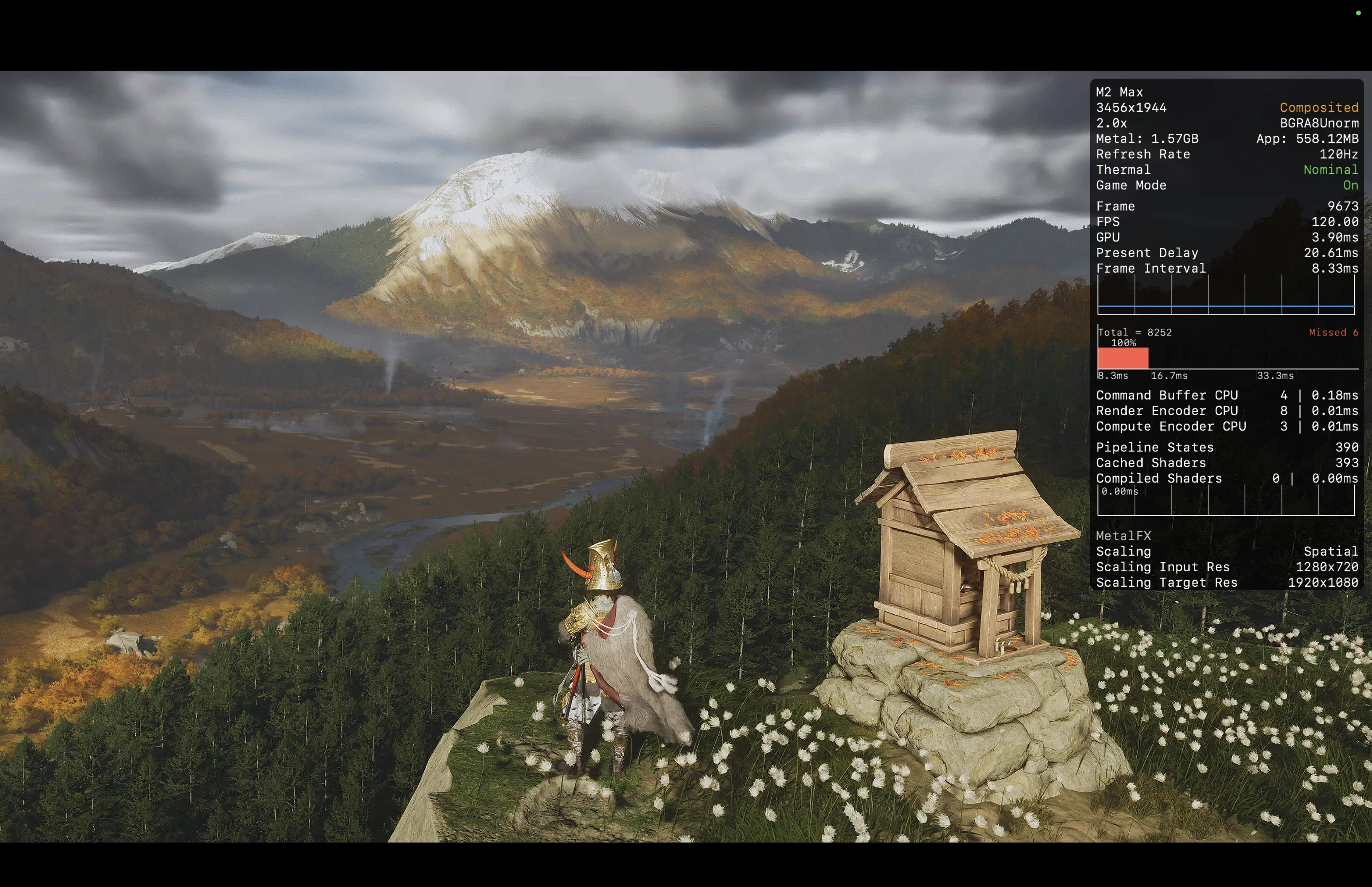
在 ConsoleLink 中调用的 MetalFX Spatial(空间超分) 是这种极端场景下的唯一解法。它不需要历史帧和引擎数据,而是纯粹依靠高阶空域卷积核,进行亮度边缘梯度分析与方向性插值。由于接收的是已经被 PSSR 完美消噪、抗锯齿化的高质量 1440p”底片”,MetalFX 完美规避了低分辨率下容易放大的噪点问题,化身为极高效率的边缘导向锐化放大器,将 1440p 的 3,686,400 个物理像素,丝滑填补至 4K 级别的画布上。

M2 Max 统一内存的零拷贝奇迹(Zero-Copy)
这套系统的底层延迟能压榨到媲美高端电竞显示器,M2 Max 的 UMA(Unified Memory Architecture,统一内存架构) 居功至伟。在传统的 x86 + NVIDIA 架构中,外设输入的视频流必须先写入系统主板 RAM,然后再跨越 PCIe 总线拷贝至独立显卡的 VRAM 中,这一来一回的物理搬运不仅增加延迟,更带来巨大的功耗吞吐。
而在这台 MacBook Pro 上,圆刚采集卡传入的无压缩帧直接驻留在 M2 Max 庞大的统一内存池中。CPU 仅仅是将这段物理内存的指针交给 GPU 着色器,物理层面的数据搬运被彻底抹除。GPU 的 ALU 单元直接原地对像素进行 MetalFX 放大计算,并直通 XDR 屏幕控制器。整个流转过程,CPU 占用率无限趋近于 0%,而系统总功耗在执行如此高强度的 120 Hz 实时空间超分时,依然稳定在 Apple 定义的”Nominal”(正常)发热区间。
在这套降维打击的系统面前,“Mac 不能打游戏”的古板偏见,终于被算力与想象力彻底粉碎。
Powered by Astro & Fuwari
粤ICP备2026022762号-1
 粤公网安备44011202003680号
粤公网安备44011202003680号